
Moin Leute,
heute habe ich auch mal 'ne Frage.
Es geht um ein PDF-File, welches ich von meiner Sparkasse bekommen habe. Das Dingen lässt sich um's Verrecken nicht unter Linux öffnen, weder unter Squeeze noch unter Wheezy. Notgedrungen habe ich die Datei in eine virtuelle WinXP-Maschine geladen und dort versucht, das Teil mit PDF-Exchange-Viewer zu öffnen. Funktioniert auch nicht. Daraufhin habe ich den neuesten Foxit-Reader in diese virtuelle Maschine installiert, damit funktioniert das - allerdings nur bedingt.
Jetzt habe ich gedacht: Versuch macht kluch...:-)) und habe mir auf dieser virtuellen XP-Maschine den Adobe-Reader installiert, damit ging die Datei natürlich auf und es stellte sich heraus, dass ich diese dort sogar bearbeiten konnte, was mit dem Foxit nicht zu bewerkstelligen war.
Hier mal ein Bild von dem, was unter Debian und unter WinXP mit dem Exchange-Viewer aufgeht:
http://www.nickles.de/user/images/84526/bildschirmfoto-am-2012-03-16-16:57:37.png
Da steht oben in der ersten Zeile, dass es sich um ein Dokument "....erzeugt von OSPDMS 11.0 final..." handelt. Gebe ich den Begriff bei Google ein, dann kommen immer irgendwelche PDFs, die man sich ansehen kann, allerdings keine Beschreibung, um was für ein Format (irgendein spezielles PDF-Format natürlich..) es sich nun handelt und wie man das Dingen unter Linux ohne den Adobe-Reader öffnen kann.
Vielleicht hat ja hier jemand einen Tipp.
Gruß
K.-H.

 Borlander
Borlander KarstenW
KarstenW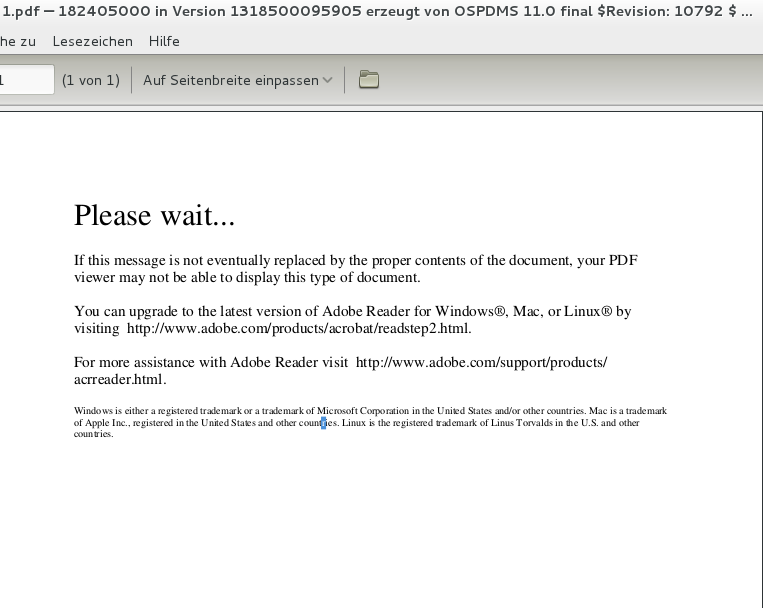{kind=link}